How many times have you come across a math problem and didn’t know what the hell you were looking at? I would watch a show called Numbers where 2 brothers would work together to solve crimes. One was an FBI agent, and the other was a genius mathematician who solves all crime with math. The Genius brother would talk to everyone in the room to explain why the equation was being used in really simplistic terms. To this day I and most likely the FBI brother would have no idea whether the math on the board was real or not. Now the FBI brother and I could pop those equations into an LLM (Large Language Model) and understand what his brother is talking about. I am still not ever going to go to a mathematician to solve a crime, just saying. Back to the subject. Keeping with the AI theme of this blog I wanted to know what the linear classifier formula is actually doing for Machine Learning.
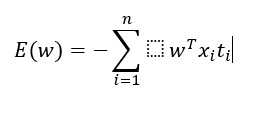
To do some testing with a few of the popular AI’s out there I wanted to break down this equation. I am going to test Chat GPT, Bing Chat and Bard.
- ChatGPT is Open AI’s LLM (https://chat.openai.com)
- Bing Chat is Microsoft’s LLM based on ChatGPT (https://bing.com/chat)
- Bard is Google’s LLM (https://bard.google.com)
If you have been looking into AI you may have noticed a lot of people talking about prompting. What is this mysterious prompting? Simply, its how we talk to or interact with the AI. So lets go through a few examples.
Example 1 – A math problem through ChatGPT
Example 2 – A math problem through Bing Chat (Bing Chat uses ChatGPT in the background)
Example 3 – A math problem through Googles Bard
I am taking the perception criterion (fancy math problem) as my sample math problem. This is used in AI to figure out the amount of error when determining perception.
To train a perceptron we need to find a weights vector w that classifies most of the values correctly, i.e. results in the smallest error. This error is defined by perceptron criterion in the following manner:
E(w) = -∑wTxiti (Friendly version instead of the jpg above)
For most of us, this is way beyond our level of comprehension. So lets use the AI that is available to us to make sense of this. We will be doing this by asking the following questions:
Question 1: What is this math problem? E(w) = -∑wTxiti
Question 2: Can you give me more context and explain the symbols better?
Question 3: Explain it to me as if I was a 5 year old?
I asked each AI the following 3 questions. The AI LLM’s keep context so you don’t have to reinput data. So each question actually builds off the previous questions. This holds true as long as you don’t close your session.
Why not just search it
Wait….Why not just do a search and find an article or something? Well, I thought I should test that. I only asked question one in Bing and Google. I didn’t move on to question 2 or 3 because the search engines do not have context and based on my initial results, I didn’t think it was worth the effort.
Bing results:
- Bing search gave me calculators for the first several results. Lots of sites with scientific calculators to do the problem myself! Not very helpful. I got rid of the question and just inputted the equation. Bing with just E(w) = -∑wTxiti and not the question in front showed a Jimmy Fallon Video for the top result? I might check that out. Then a few blogs where individuals ask about the equation. None of those blogs had good links or examples answering the question. Just searching for the equation did not appear to show any relevant results. Fail!
Google results:
- Google took me to math solving sites. No appearance of anything relevant to the specific math problem. All the sites on in the top Google results wanted me to register and/or pay. 😒 Google with just the equation: “It looks like there aren’t many great matches for your search” was its response. Then random sites. Really not helpful. At least Google admitted that it had no results for me. Not even a Jimmy Fallon video. Fail!
Side note: Bing Chat gave me sites that had the right answers in its reference section. Will AI replace search engines? I think I have my next blog post and testing.
Results
Each AI LLM gave some lengthy responses. I put the results at the end of this post so you can review for yourself. Here are some key items I noticed per LLM.
ChatGPT:
- ChatGPT didn’t know what the equation was exactly but took a good guess and got it right. But based on the response, they make it clear it is not a %100 answer.
- When asking for more details, it does a great job at adding more detail.
- When asking for clarification as a 5-year-old, I was floored. Awesome response. You could make a game for kids to play and learn AI. Pretty cool! You should check out the response below.
- Responses use a bulleted format, which after years of technical writing I do as well. So I enjoy the response breakdown structure
- Context is spot on and does not deviate from the topic, which makes adjusting your prompting in the session great.
- Responses are a bit long winded. IMHO.
Bing Chat
- Bing Chat is based on ChatGPT so you will get the same feel (lack of a better word) as ChatGPT.
- Bing Chat knows what the equation is and clearly calls this out. This is due to referencing several sites that list the equation, so Bing has access to more knowledge than its competitors. Funny the search engine didn’t do that?
- The first question response explains the equation, but not with as much detail as Chat GPT for the first question.
- Question 2 provides more details and does a good job of making it brief while still detailed
- When asking how to explain it to a 5-year-old, it was spot on. Bing Chat provides multiple examples that are super simple and to the point. I can imagine the genius brother from Numbers giving the same response. Not as creative as ChatGPT but I think I would use Bing’s response to explain this to my own kids if they ever asked.
Bard:
- Google, Google, Google…(as I shake my head) Its response gets it right but then lets me know it could be applied in other fields. What are those fields, it doesn’t really say. I read the responses to only have more questions.
- Bard was the least detailed response for question 1. Where it does redeem itself is it gives me examples of ways, I can make the prompt better by providing more detail. I did not experience this with the other LLM’s.
- I would like references like Bing Chat provides.
- Question 2 provided details on other places the equation can be applied. These are the 4 it gave me. Machine Learning (Logistic Regression), Linear Regression, Physics, and Other Mathematical Contexts. Once again, it gives good examples of how you can use prompting to get a better answer. Good job Google!
Overall other observations:
- Pro: Open AI’s Chat GPT gave me great detail
- Con: Open AI is still a pay for service, where Bing Chat and Bard are currently free.
- Pro: Microsoft’s Bing Chat provided references which I liked to dig in further
- Pro: Google’s Bard provided examples of how I could make the prompt better.
Final thought
Using LLM’s to help with math problems and learning is very viable. I wish I had access to this level of help when I was a student (Grade school, High School, and College). Context by staying in the same session is very cool and playing with your question (prompting) yields interesting results. If a particular piece of an equation doesn’t make sense have the LLM dive in for you more. Ask for examples. I did this and wanted to include them, but this post is already getting long. I have found that the LLM’s can get confused after too many shifts in prompting. Starting a fresh session can be helpful but you will have to reset the context for the LLM again. I have provided the responses below for your to review. They are lengthy but it is worth reviewing. Also, please remember they update these LLM’s constantly so answers will get better and sometimes worse as things change. Based on search results using Bing and Google, I hope they focus on providing the information and not their business model as these capabilities develop. Hope you enjoyed. Thank you.
_______________________________________________________________________________________________________________
Responses
Chat GPT
Response 1: What is this math problem? E(w) = -∑wTxiti
The mathematical expression E(w)=−∑wTxi ti represents a formula often used in the context of machine learning, specifically in the training of models such as linear classifiers or neural networks.
Here’s a breakdown of the components of this expression:
- E(w) – This usually represents the error or cost function, which quantifies how well the model’s predictions align with the actual outcomes. The function depends on w, which represents the parameters or weights of the model.
- w – The vector of weights or coefficients in the model. These weights are what the learning algorithm adjusts to minimize the error.
- ∑ – This symbol represents summation. The expression inside the summation is calculated for each instance in the dataset, and the results are summed up to provide a total measure.
- wTxi – This is the dot product of the weight vector w and a feature vector xi . xi represents the input features of the i-th data point in the dataset. wT is the transpose of w, making this a dot product.
- ti – This typically represents the target or true value for the i-th data point. It’s what the model is trying to predict.
The negative sign in front of the summation indicates that this might be a maximization problem being converted into a minimization problem, which is common in optimization tasks in machine learning.
In summary, E(w)=−∑wTxi ti is likely a cost function used in a machine learning context, which is being minimized to train a model by adjusting the weights w to best fit the data represented by xi and ti.
_______________________________________________________________________________________________________________
Response 2: Can you give me more context and explain the symbols better?
Certainly! Let’s delve deeper into the components of the mathematical expression E(w)=−∑wTxi ti to provide a clearer understanding:
- E(w):
- This is a function of w.
- E typically stands for “error” or “energy” in many machine learning contexts. It’s a measure of how well the model is performing.
- w represents the set of parameters or weights of your model. The performance of the model heavily depends on these values.
- w:
- This is a vector representing the weights or coefficients in your model.
- In machine learning, especially in models like linear regression or neural networks, these weights are what you adjust during training. The goal is to find the set of weights w that minimizes E(w).
- The Summation ∑:
- This symbol indicates that you’re adding up multiple terms.
- It’s a way to aggregate the total error or cost over all data points in your dataset.
- Each xi ti term inside the summation corresponds to a single data point in your dataset.
- wT:
- wT is the transpose of the weight vector w.
- Transposing a vector means converting a row vector to a column vector or vice versa.
- The transpose is necessary here for the mathematical operation of dot product to be valid between vectors w and xi .
- xi :
- This represents the feature vector of the i-th data point in your dataset.
- In the context of machine learning, this would include all the input features used by the model for prediction.
- ti :
- This usually represents the true label or target value for the i-th data point.
- It’s what the model is trying to predict. In the context of supervised learning, this would be the known outcome you’re training your model to replicate.
Putting it all together:
- The expression −wTxi ti within the summation calculates a term for each data point in your dataset, which contributes to the total error/cost.
- The negative sign might indicate a specific formulation of the error function, possibly relating to maximizing some quantity (like likelihood in logistic regression) by minimizing its negative.
- The summation sums up these individual error contributions across all data points to give a total measure of how well the model, with a given set of weights w, is performing across the entire dataset.
- The goal in training the model is to adjust w to minimize E(w), thereby finding the best set of weights that make the model’s predictions as close as possible to the true outcomes.
_________________________________________________________________________________________________________
Response 3: Explain it to me as if I was a 5 year old
Of course! Let’s imagine you have a bunch of toy houses, and each one has a price tag. Now, you’re playing a guessing game where you try to guess the price of each house based on how big it is and how many rooms it has.
- Toy Houses (Data Points): Each toy house is different. Some are big, some are small, some have many rooms, and some have just a few.
- Price Tags (Target Value): Every house has a price tag. This is the amount you’re trying to guess.
- Guessing Rules (Weights): You have a special pair of dice that help you guess. The first die helps you guess based on the size of the house, and the second die helps you guess based on the number of rooms.
- Making a Guess: When you pick a house, you roll your dice. The first die might say “multiply the size of the house by 2” and the second die might say “multiply the number of rooms by 5”. You add these two numbers together to make your guess.
- Checking Your Guess: After you guess, you look at the price tag to see how close you were. If your guess is too high or too low, you know you need to change your guessing rules (roll the dice again).
- The Game (Training the Model): You keep picking houses, rolling your dice (changing your guessing rules), and checking your guesses. Each time you do this, you try to get closer to the right prices. The goal is to get really good at guessing the prices of the houses just by looking at how big they are and how many rooms they have.
- Winning the Game (Optimizing the Model): When your guesses are usually very close or exactly right, you’ve won the game! This means you’ve found the best dice numbers (weights) to guess the price of any new toy house you play with.
So, in this little game, rolling the dice and trying to guess the price of the toy houses is like the math equation E(w)=−∑wTxi ti – it’s all about finding the best way to guess!
Bing Chat
Response 1: What is this math problem? E(w) = -∑wTxiti
The expression E(w) = -∑wTxiti is a mathematical formula that is used in the field of machine learning. It is used to calculate the empirical risk of a linear model, where w is the weight vector, x is the input vector, t is the target vector, and i is the index of the training data point 1. The formula calculates the sum of the product of the weight vector and the input vector multiplied by the target vector, and then negates the result 1.
The symbol ∑ represents the summation of the product of w, x, and t over all the training data points 1. The symbol T represents the transpose of a matrix, which is used to convert a row vector into a column vector or vice versa 1. The symbol E(w) represents the empirical risk of the linear model, which is the expected value of the loss function over the training data 1.
In summary, E(w) = -∑wTxiti is a formula used to calculate the empirical risk of a linear model in machine learning, where w is the weight vector, x is the input vector, t is the target vector, and i is the index of the training data point 1.
_______________________________________________________________________________________________________________________________
Response 2: Can you give me more context and explain the symbols better?
Certainly! Here is a more detailed explanation of the symbols used in the formula E(w) = -∑wTxiti:
E(w) represents the empirical risk of the linear model, which is the expected value of the loss function over the training data 1.
w is the weight vector, which is a vector of coefficients that are used to calculate the output of the linear model 1.
x is the input vector, which is a vector of features that are used to predict the target variable 1.
t is the target vector, which is a vector of actual values for the target variable 1.
i is the index of the training data point, which is used to iterate over all the training data points 1.
∑ represents the summation of the product of w, x, and t over all the training data points 1.
T represents the transpose of a matrix, which is used to convert a row vector into a column vector or vice versa 1.
– negates the result of the summation 1.
In summary, E(w) = -∑wTxiti is a formula used to calculate the empirical risk of a linear model in machine learning. The formula calculates the sum of the product of the weight vector and the input vector multiplied by the target vector, and then negates the result. The symbol ∑ represents the summation of the product of w, x, and t over all the training data points, and the symbol T represents the transpose of a matrix. The symbol E(w) represents the empirical risk of the linear model, which is the expected value of the loss function over the training data.
________________________________________________________________________________
Response 3: Explain it to me as if I was a 5 year old
Machine learning is like teaching a computer to learn things on its own. It’s like when you learn how to ride a bike, and you get better at it the more you practice. The computer learns by looking at lots of examples and figuring out how to do things by itself. It’s like when you learn how to draw a picture by looking at other pictures and then you can draw your own picture. The formula you asked about is used to help the computer learn how to do things better. It’s like a special recipe that helps the computer get better at guessing things. Does that make sense? 😊
Google Bard
Response 1: What is this math problem? E(w) = -∑wTxiti
While I can’t definitively determine the exact problem without more context, I can provide a breakdown of the components and potential interpretations based on common mathematical conventions:
Components:
E(w): This likely represents a function named “E” that takes a vector “w” as input and produces a scalar output.
w: This is likely a vector of numerical values, often referred to as weights or parameters in machine learning and statistical contexts.
Txi: This could represent a matrix-vector multiplication, where “T” is a matrix and “xi” is a vector.
ti: This is likely a vector of numerical values, possibly representing target or observed values.
∑: The summation symbol indicates that a sum is being calculated over a collection of terms.
Potential Interpretations:
1. Machine Learning (Logistic Regression):
If this equation is encountered in machine learning, specifically logistic regression, it’s likely representing the cost function, also known as the negative log-likelihood function.
The goal in this context is to find the values of “w” that minimize this function, leading to a model that best fits the training data.
2. Linear Regression:
In linear regression, a similar equation with a summation of squared errors is used to measure how well a linear model fits the data.
3. Other Potential Contexts:
The equation could represent other concepts in mathematics or physics, depending on the specific domain and usage.
To provide a more precise explanation, please provide additional information about:
The subject area or context in which you encountered this equation.
Any specific instructions or questions related to the equation.
The broader problem or task for which this equation is being used.
________________________________________________________________________________________________________________
Response 2: Can you give me more context and explain the symbols better?
I’ll provide a broader explanation of the symbols and potential contexts, incorporating insights from common mathematical conventions:
Symbols:
- E(w): This typically denotes a function named “E” that depends on a vector “w” as its input. The output of this function is likely a scalar value.
- w: This is usually a vector of numerical values, often referred to as weights or parameters in various fields like machine learning, statistics, and physics.
- T: This could represent a matrix, potentially containing coefficients or transformation information.
- xi: This is likely a vector of numerical values, possibly representing input data, features, or independent variables.
- ti: This is also likely a vector of numerical values, potentially representing target values, observed values, or dependent variables.
- ∑: The summation symbol (sigma) indicates that a sum is being calculated over a collection of terms.
Potential Contexts:
1. Machine Learning (Logistic Regression):
- In logistic regression, a common machine learning algorithm for binary classification, this equation likely represents the cost function, also known as the negative log-likelihood function.
- The goal is to find the values of the weights “w” that minimize this function, leading to a model that best fits the training data and accurately predicts the outcomes.
2. Linear Regression:
- In linear regression, a similar equation with a summation of squared errors is used to measure how well a linear model fits the data. The goal is to find the line of best fit that minimizes the sum of squared differences between the predicted values and the actual values.
3. Physics:
- In physics, this equation could potentially represent a calculation of energy or potential energy, depending on the specific context and definitions of the variables.
- For example, in electrostatics, “w” could represent charge density, “T” could represent a matrix of potential coefficients, and “xi” and “ti” could represent position vectors.
4. Other Mathematical Contexts:
- The equation could represent various other concepts in mathematics, such as optimization problems, vector calculus, or matrix operations, depending on the specific domain and usage.
To further clarify the meaning and purpose of this equation, please provide details about:
- The subject area or context in which you encountered it (e.g., machine learning, physics, mathematics).
- Any accompanying text, instructions, or formulas that might provide more context.
- The broader problem or task for which this equation is being used.
With this additional information, I can offer a more accurate and tailored explanation.
_________________________________________________________________________________________________________________
Response 3: Explain it to me as if I was a 5 year old
Imagine you have a bunch of different buckets, each one representing a special toy. Some buckets have lots of blocks, some have cars, and some have teddy bears. Now, let’s say you want to know which bucket is the BEST for playing with.
This equation is like a special game that helps us figure out the best bucket. We have different clues about each bucket (like how many toys it has) and we want to add them up in a smart way to see which one wins.
Here’s what the parts mean:
- E(w): This is like the score of the game. The higher the score, the better the bucket.
- w: This is like the value of each clue. Some clues, like having lots of different toys, might be worth more points than others.
- T: This is like a special tool that helps us combine the clues in just the right way.
- xi and ti: These are like the clues themselves, telling us something about each bucket.
- ∑: This is like saying “add all the clues together” to get the score.
So, by playing this game with the equation, we can compare all the buckets and find the one that has the highest score – that’s the one that’s the most fun to play with!
Remember, this is just a simplified explanation to give you the main idea. When you grow up and learn more about math, you’ll be able to understand the equation even better and play all sorts of interesting games with it!
Woah! I’m really enjoying the template/theme of this website.
It’s simple, yet effective. A lot of times it’s very hard to get
that “perfect balance” between user friendliness and
appearance. I must say you’ve done a great job with this.
In addition, the blog loads extremely quick for me on Safari.
Superb Blog!